Every data team in your company has an ETL pipeline.
Your marketing analytics team extracts data from ad platforms, transforms it into a unified schema, and loads it into a warehouse. Your revenue ops team does the same thing with CRM records. Your product team does it with event data. The pattern is so fundamental that entire companies, Fivetran, Airbyte, Stitch, have been built around automating it.
ETL: Extract, Transform, Load, is not a new concept. It has been the backbone of data engineering for decades. Pull data from a source. Reshape it to fit the destination. Push it in.
There are hundreds of tools for this. Thousands of engineers who specialize in it. An entire job title built around it.
Now try to do the same thing with your website.
The gap nobody talks about
Your website is one of the most important data assets your company owns. Every page, every blog post, every meta description, every redirect, every localized variant, every module, every content relationship. It is structured data. It follows schemas. It has dependencies.
But nobody treats it that way.
When a data team needs to move CRM records from Salesforce to HubSpot, they use a migration tool. They map fields. They run transformations. They validate the output. The tooling exists because the industry decided this was a problem worth solving.
When a content team needs to move 10,000 pages from one CMS to another, they get a spreadsheet and a timeline.
The content team exports what they can into CSVs. They manually copy what the export misses. They write one-off scripts that break when the source data has edge cases nobody anticipated. They hire an agency that quotes three months and delivers in six.
This is not a people problem. Content teams are not less capable than data teams. They just never got the tooling.
Why website content is harder than it looks
Part of the reason ETL tooling does not exist for websites is that website content is deceptively complex.
A CRM record is a row with fields. A contact has a name, an email, a company, a lifecycle stage. The schema is flat and predictable. Moving it from one system to another is a mapping exercise.
A website page is not a row. It is a nested, relational, modular structure. A single page in HubSpot CMS might contain a hero module, a rich text section with embedded images, a CTA component, a form, a footer pulled from a global partial, metadata in the settings panel, and a URL structure that determines its position in the site architecture.
Move that page to a headless CMS like Contentstack, and every one of those elements needs to be mapped differently. The hero module becomes a modular block. The rich text might need to be parsed for embedded assets. The global partial becomes a global field. The metadata moves into a dedicated content type. The URL structure is rebuilt from scratch.
Multiply that by 10,000 pages across 11 languages, and you start to understand why nobody has built a general-purpose tool for this. The problem space is enormous.
But that does not mean the ETL pattern does not apply. It means nobody has applied it yet.
What website ETL actually looks like
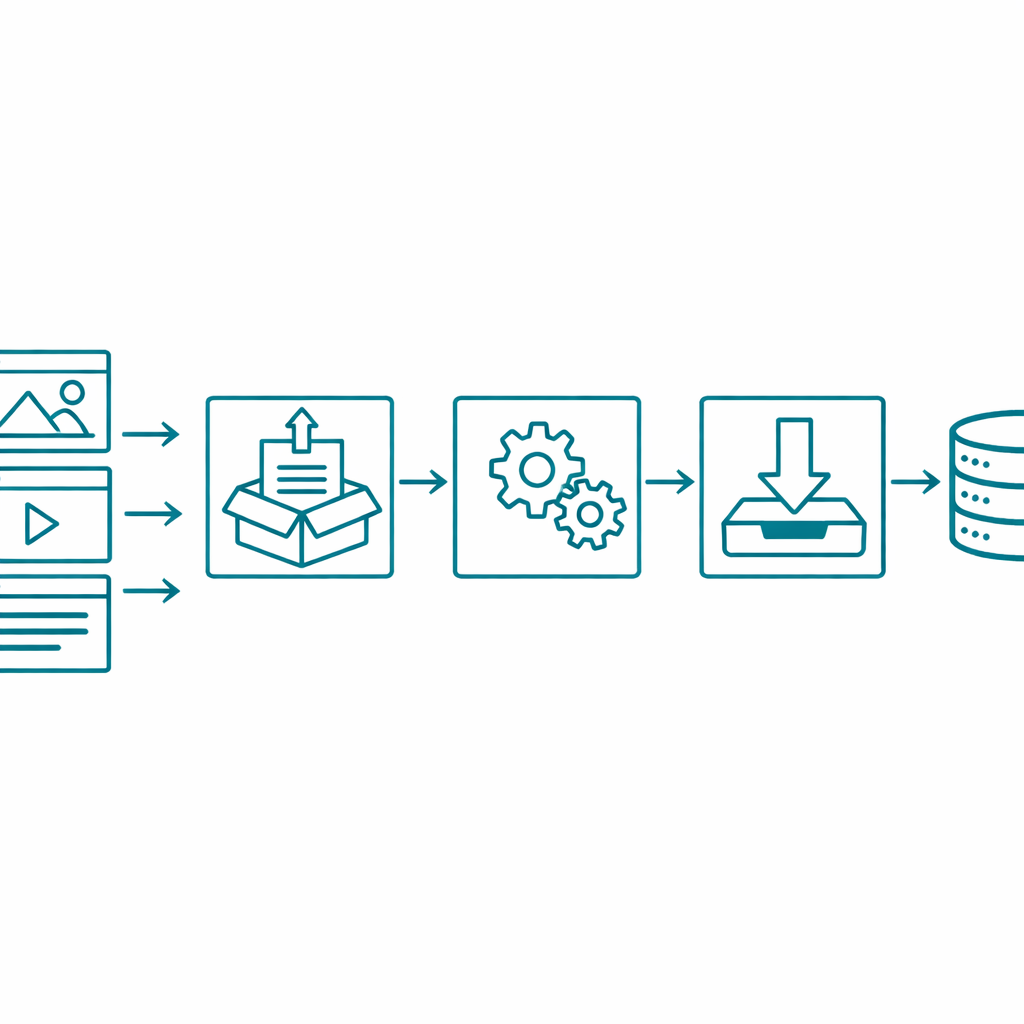
The pattern is the same as any other ETL pipeline. The complexity is in the content model, not the concept.
Extract means pulling everything out of the source CMS. Not just the content you can see in the editor, but the modules, the templates, the relationships between content types, the localization structure, the redirect rules, the HubDB tables, the metadata. A full extraction is an inventory of the entire content architecture, not a CSV export. This is where having a spreadsheet view of your CMS changes everything, because you can actually see the full scope of what you are working with before writing a single line of migration code.
Transform means reshaping that content to fit the destination. This is where most migrations break down, because transformation is not just reformatting text. It is consolidating five banner modules into one. It is converting HubSpot's page-per-language model into a locale-based system. It is deciding which of 166 modules are actually needed and mapping them to a clean component library.
We went through this exact exercise on a project with over 31,000 content entries. The source site had 57 content types, 166 modules, and 48 HubDB tables. The transformation phase took 166 modules down to 40. Not by cutting content, but by identifying duplicates and consolidating. Five accordion modules doing the same thing became one configurable component.
Load means pushing the transformed content into the destination platform with the right structure, the right relationships, and the right references intact. When a blog post references an author, that author needs to exist as a content entry in the new system before the post is loaded. When a page uses a hero module that references an image asset, that asset needs to be loaded first. The order matters.
Why this matters beyond migration
ETL is not just for moving content between platforms. The same pattern applies to any operation where content needs to be extracted, reshaped, and reloaded.
Running a sitewide metadata audit means extracting all page-level SEO data, analyzing it against a set of rules, and pushing corrections back. That is ETL. Consolidating a blog after a company acquisition means extracting posts from two different CMS platforms, normalizing the content model, and loading them into one unified system. That is ETL.
Even routine content operations, updating meta descriptions across 500 pages, replacing an outdated term sitewide, restructuring URL paths after a rebrand, follow the same extract-transform-load logic. The content comes out, gets changed, and goes back in.
The difference between doing this manually and doing it with proper tooling is the difference between weeks and hours.
Where the industry is heading
Content engineering as a discipline is starting to formalize. More teams are treating their website content as a managed data layer rather than a collection of individual pages. The rise of headless CMS platforms, structured content models, and composable architectures is pushing the industry toward the same patterns that data engineering adopted years ago.
At Smuves, this is the problem we are working on. We started with bulk editing for HubSpot CMS, giving content teams a way to inspect and edit pages at scale instead of one at a time. That work naturally led to content auditing, understanding what a site actually contains before making changes. And auditing naturally led to migration, moving content between platforms with the structural integrity intact.
The thread connecting all of it is the same: treat website content as structured data, and the tools you need start to look a lot like the tools data teams have had for years.
The concept is not revolutionary. It is overdue.
What a website ETL tool needs to do
For anyone thinking about this problem, whether building internal tooling or evaluating vendors, here is what a website ETL system needs to handle.
It needs full content extraction that goes beyond page titles and body text. Modules, templates, relationships, localization, metadata, redirects, database tables, all of it.
It needs content model transformation that can consolidate, remap, and restructure content types rather than just moving them as-is. Lift-and-shift is rarely the right answer. The question of who actually owns the CMS and how years of uncoordinated building creates architectural debt is exactly why transformation matters more than a straight copy.
It needs dependency-aware loading that respects the order of operations. Assets before pages. Authors before posts. Global components before the entries that reference them.
And it needs logging. Every extraction, every transformation, every load operation should be logged and reversible. Content migration without logging is just an expensive copy-paste.
The bottom line
ETL is the most common data pattern in modern software. Every team that moves structured data between systems uses it. Except the team managing the most publicly visible data asset the company owns.
That gap is closing. Content engineering is catching up to data engineering. And when it does, the idea of migrating a website by manually copying pages will feel as absurd as migrating a database by manually copying rows.
We are not there yet. But the pattern exists. The thinking exists. The tooling is being built.
It just took the website world a decade longer to get here.